In this post, I’ll talk a bit about what kinds of topics and ways of thinking constitute the field of computer graphics. Since I’ve only been in this field for a few years, it might be somewhat idealistic; it’s a product of my personal observations from professors, papers, and conferences. This is the first in a series of three posts about why I’m doing a PhD in Computer Graphics.
Defining Computer Graphics
When most people think about computer graphics as a field, they think about rendering: making computer-generated images.

Rendering was the most important problem in computer graphics at the beginning of the field, but nowadays graphics is much broader in scope. A lot of the hottest new technology, like 3D printing and virtual reality, are a part of Graphics.
Here is my general definition of Computer Graphics as a research field:
Computer Graphics is about modelling the physical world, using these models to capture the real world and to create physically meaningful things
To understand what this definition means, let me break it down into parts.
-
Modelling: A model is an explanation of how something works. Models are often mathematical and can be used to make precise predictions of how some phenomenon will occur.
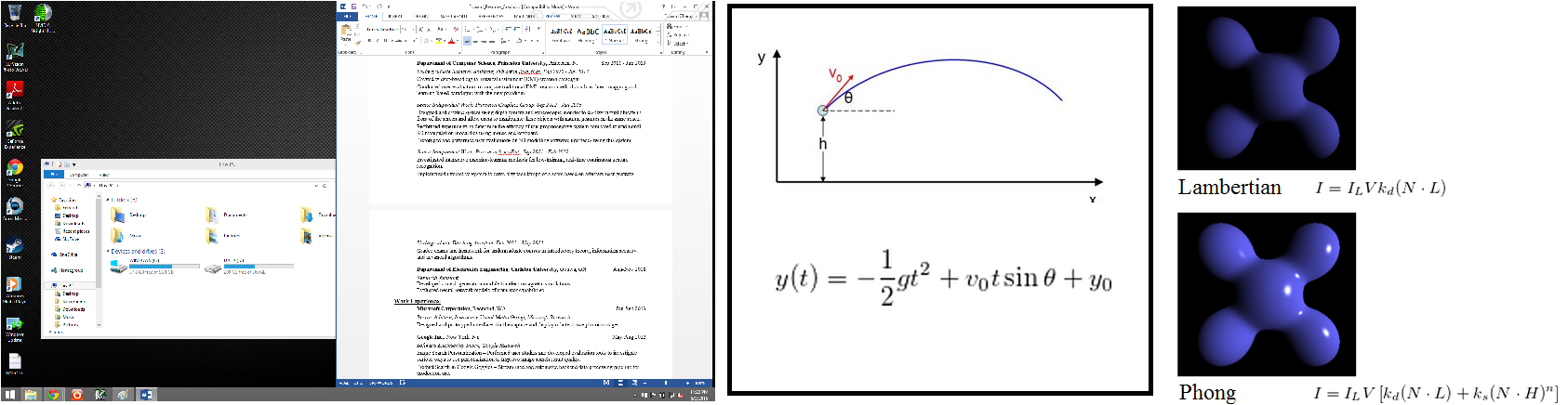
You probably operate your computer using a desktop model; you can put documents and folders on your desktop, and examine a “paper document” by opening it up in a window. A common high-school physics model says that if you throw something, it will travel on a parabolic trajectory. One simple model used in computer graphics, the Lambertian reflectance model, says that apparent color of an object is its intrinsic color times the amount of light shining on the object, while a more complicated model, such as the Phong model, might also allow objects to be shiny.
Models are often extreme simplifications of how things really work, but that does not stop them from being useful.
-
Physical World: The physical world consists of the things we can see, hear, touch, smell, and taste around us. Computer graphics is particularly interested in how light works (how it travels through space and bounces off of surfaces), but we are also interested in questions like “How do objects break when they hit each other?”, “How do liquids behave?”, and “How does sound propagate through the world?”.
We can contrast physical characteristics of the world with semantic characteristics. Semantic characteristics are those that we as humans determine using reasoning and logic; for instance, identifying a particular arrangement of rocks as a skyscraper is a semantic identification. In contrast, physical characteristics are the same whether or not there is a human to interpret them; for instance, the shape of an object (how smooth or jagged is it?) and the color of an object (what wavelengths of light does it reflect?) are physical characteristics.

-
Capture the real world: Once we have models of the physical world, we can explore how we can use them. Often (but not always), we want to apply them to real life. To do this, we need to specialize our models to the world around us. In practical terms, models often have several numbers that can be tweaked (e.g. how strong is gravity? how bright is this light?), and capture is the process of finding values for these numbers that fit the real-world behavior of the phenomenon we are modelling.
-
Create physically meaningful things: This phrase is deliberately vague, since there are so many things we can do with these models! For instance, a 3D sculpture of yourself is physically meaningful - it looks like you! Computer-generated movies are physically meaningful - even a fictional character like Gollum can look like a real creature, with realistic skin, hair, movements, and expressions! And so on. Anything we can interpret naturally using our senses as a representation of some world, whether it is our own reality or a fictional one, is physically meaningful.

Why Graphics is Special
In Computer Science, we usually work at a very high level of abstraction. In a computer, we have a bunch of electrical components and signals, which we then interpret as ones and zeros, which we then interpret as numbers or letters, which we then continue to combine at higher and higher levels until we get video game characters or e-books or webpages. We design algorithms and data structures that can, using the same code, operate on Google maps, your Facebook friends, Netflix movies, and a lot more. While it’s great that we can create individual algorithms that can help solve a large variety of different problems, it means that most of the time, we’re far removed from the real life applications of our work.
Graphics is one of the few subfields of computer science that deals concretely with the real world. Every human develops an intuition about the physical world starting from birth, learning about gravity and physics, seeing the behaviors of lights and shadows, finding out how things look from different angles, and observing how things bounce or break when they hit other things. This means that the applications of computer graphics - the software we write, the results we present - are things everyone can appreciate, regardless of their technical knowledge.
Of course, Graphics is not alone in its direct real-world applicability. Other subfields of Computer Science, such as Robotics and Human-Computer Interaction, also deal with the real world in a meaningful way. It is in fact very common for research in these fields to overlap with Graphics.
Graphics and Vision
You might have noticed that my definition of graphics actually includes a lot of computer vision, or that I lumped vision and graphics together in my discussion of CS subfields above. This might be at odds with the idea that graphics should be about making new pictures (“creating”), and vision should be extracting information from existing pictures (“capturing”).
In terms of the everyday usage of these words, this differentiation is useful. However, in terms of academic disciplines, modern graphics and vision have a lot of overlap; in fact, vision started as a subfield of graphics. Many papers in graphics conferences could just as well be published in vision conferences, and vice versa.
A more refined way of differentiating the two academic fields is by looking at what sorts of information we aim to get from the images.
- Graphics is interested in physical properties of objects in the image. This means things like 3D reconstruction (determining the shapes of things in the image), or Appearance Capture (how the surfaces in the image reflect light).

- Vision is interested in the semantic meaning of objects in the image. This means things like Object Recognition (identifying whether a picture contains a cow, dog, person, or car), Object Detection (identifying where in the image the cow/dog/person/car is) and Segmentation (finding the boundaries between individual objects or regions in the scene).
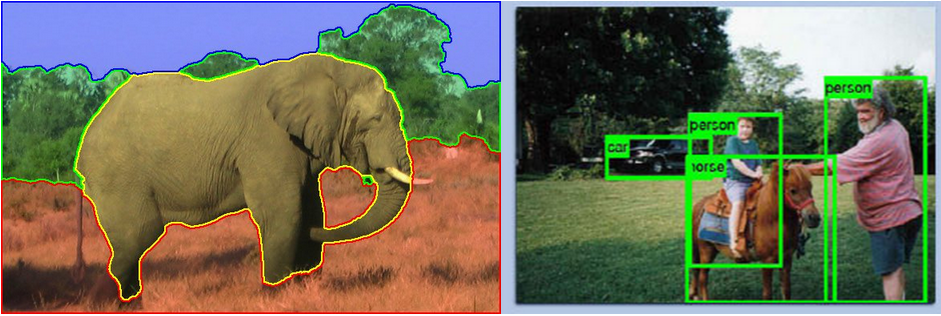
In practice, semantic information extraction is squarely in the domain of vision, while physical information extraction (e.g. 3D reconstruction) papers are published both in graphics and vision venues. Many modern graphics researchers (including me) describe themselves as working at “the boundary of graphics and vision” which usually means being concerned with physical properties of scenes. When I talk about the field of graphics, I will usually be referring to this overlap (as described in my definition above).
Conclusion
Graphics is a lot more than just making pretty pictures. Graphics researchers think very deeply about how the physical world works, and we make use of our understanding in practical applications as diverse as Google Streetview, Disney movies, and medical imaging. The direct applicability of graphics and vision research to the real world is the main reason why I am so excited about working in this field. I also really enjoy using my physical intuition to gain a deep understanding of how and why our models and methods work.
My next post will contain a lot of cool examples of what research is happening in computer graphics. You might be surprised at some of the work that falls under the umbrella of computer graphics, but I’ll refer back to my definition of the field to show why the graphics community has embraced all of these different research directions. You can get a taste of what I’ll talk about next by watching the SIGGRAPH 2015 Technical Papers preview: