Edward Zhang, Ricardo Martin-Brualla, Janne Kontkanen, Brian Curless. 2020. “No Shadow Left Behind: Removing Objects and their Shadows using Approximate Lighting and Geometry”.
Project webpage at http://grail.cs.washington.edu/projects/shadowremoval
TL;DR
Give us an image and an object to remove from it; we can remove not only the object but its shadows too.
Abstract
Removing objects from images is a challenging problem that is important for many applications, including mixed reality. For believable results, the shadows that the object casts should also be removed. Current inpainting-based methods only remove the object itself, leaving shadows behind, or at best require specifying shadow regions to inpaint. We introduce a deep learning pipeline for removing a shadow along with its caster. We leverage rough scene models in order to remove a wide variety of shadows (hard or soft, dark or subtle, large or thin) from surfaces with a wide variety of textures. We train our pipeline on synthetically rendered data, and show qualitative and quantitative results on both synthetic and real scenes.

Background
This work is in the same space as our previous paper on emptying rooms. In that work, we had to remove all the objects from the room, while our new work allows us to remove some objects and leave others.
In our previous work, we did try some experiments where we removed some objects, using our scanned 3D model for the objects we did not remove. The results did not look very good because of the low quality of the scanned geometry. This new paper uses deep learning to edit a real input view of a scene by using a rough 3D model (even rougher than the scans in our previous work) to give hints as to where the shadows of a particular fall.
Overview
Editing images by virtually inserting, removing, replacing, or moving around objects has a lot of applications. Doing so in a visually realistic fashion usually involves using some approximate model of the scene. If you have a model of the scene, you can semantically edit that model (whether that means relighting or changing around 3D geometry) and then render the model directly. However, as alluded to previously, directly rendering this model usually leaves something to be desired, since the model will contain some unavoidable inaccuracies.
The differential rendering process from Debevec’s Rendering Synthetic Objects into Real Scenes work has been the only method that bridges the gap between renderings of approximate (edited) scene models and the original input image*.
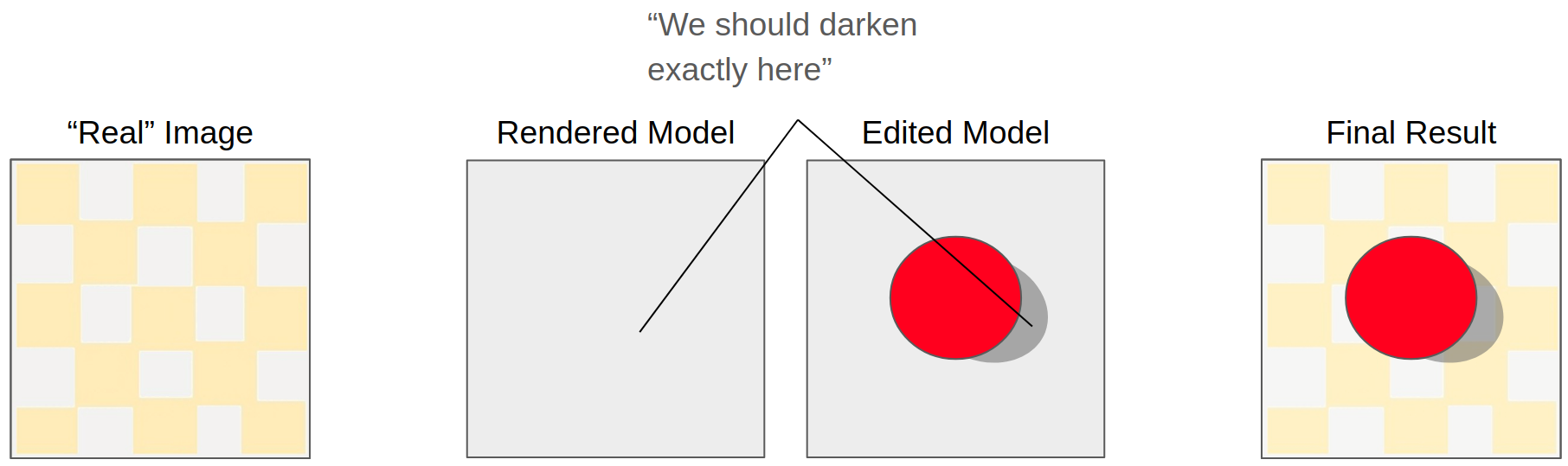
This method was designed for object insertion, and doesn’t work directly for removing objects.
We use deep CNN to do the differential rendering instead, operating on the input image as well as the renderings of the edited and unedited scene model. One benefit of this formulation is that it is purely 2D - our deep network doesn’t have to do as much reasoning about light propagation in 3D, since the rendering process does that already. One handwavey intuition is that our network just has to do a guided 2D segmentation - the renderings of the scene model give it a rough segmentation of the shadow region, and our network just has to make a more accurate segmentation on the input image.
Intrinsic Decomposition
I won’t go into too much detail about our architecture here (see the paper for full details), but I’ll highlight the key piece that gives us better results. A simple U-Net for deep differential rendering (plus a separate inpainting network) has two big problems:
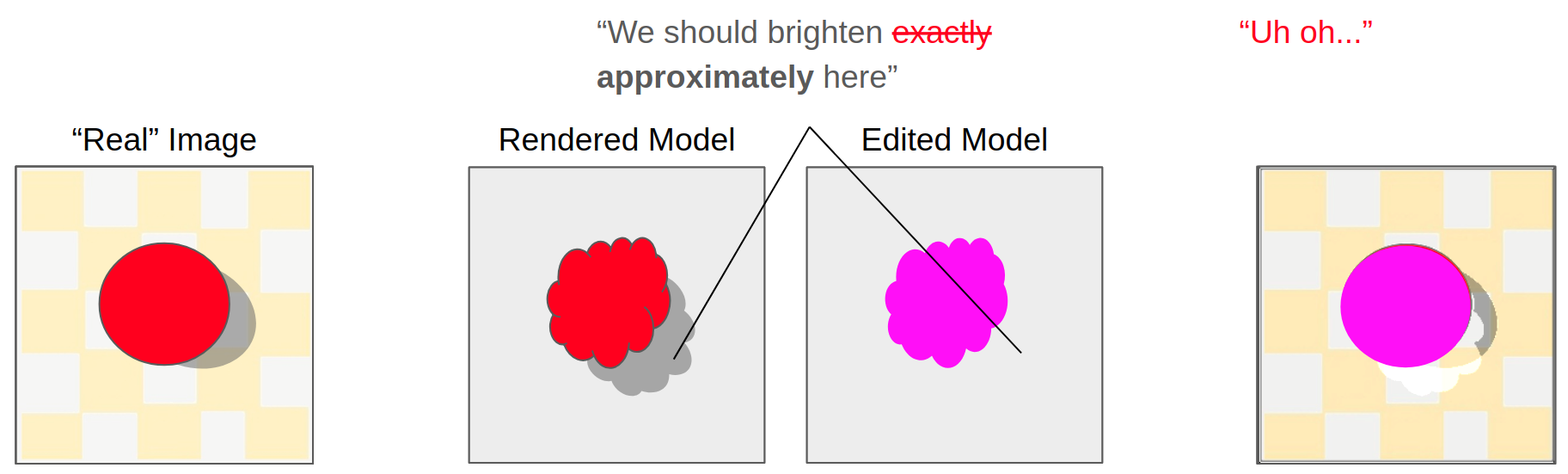
- It hallucinates shadows when inpainting. The inpainter borrows pixels from regions of the image with no knowledge about the lighting.
- It fails to fully remove shadows, especially if the surface that the shadow is cast on has a complex underlying texture. The network has difficulty figuring out whether a pixel gets darkened because it’s in shadow or whether it’s dark because the texture itself is dark.
Our key architectural change is that we first perform an intrinsic decomposition of the original input image, decomposing it into a lighting image and a texture image.

This intrinsic decomposition stage has the following benefits:
- Our inpainted then operates only on the texture image, which only contains unshadowed pixels.
- The decomposition network reasons about the texture as a whole and is better able to distinguish what variation is due to lighting and what is due to texture. This is accomplished by imposing priors on the decomposition.
- The shadow removal network then only has to remove the object’s shadow from a simpler lighting image without distracting textures.
Here is an example of our intrinsic decomposition on a real image:

Results



Acknowledgements
This work was supported by Google and the University of Washington Reality Lab.